Fiona Skerman
I am an Associate Professor at Uppsala University.
For Spring 2025 I was at SLMath/MSRI program Probability and Discrete Structures. For Fall 2021 I was a Simons-Berkeley Research Fellow in the program on Computational Complexity of Statistical Inference at UC Berkeley's Simons Institute. My previous positions were as a research fellow at Bristol University, Uppsala University, and with Dan Kráľ at Masaryk University.
My DPhil with Colin McDiarmid researched the modularity of networks and was awarded the Corcoran Memorial Prize for the best thesis in the Oxford Statistics Department [thesis]. Before coming to Oxford, I did my honours thesis with Brendan McKay at the Australian National University, looking at likely degree sequences in random bipartite graphs [thesis].
Notes
CIRM Learning on Graphs : phase transitions. See lecture notes and exercises.
Survey
Modularity and random graphs with Colin McDiarmid; to appear as a chapter in Topics in Probabilistic Graph Theory.
[arXiv]
Modularity introduced by Newman and Girvan (link) is a popular metric in community detection.
For a given graph $G$, each partition of the vertices has a modularity score, with higher values indicating that the partition better captures community structure in $G$. The modularity $q^*(G)$ of $G$ is the maximum over all vertex-partitions of the modularity score, and satisfies $0\leq q^*(G)< 1$. Modularity lies at the heart of the most popular algorithms for community detection.
In this chapter we discuss the behaviour of the modularity of various kinds of random graphs, starting with the binomial random graph $G_{n,p}$ with $n$ vertices and edge-probability $p$.
Preprints
Click on arrows to expand.
Sharp Low-Degree Thresholds for Planted-vs-Planted Testing with
Anda Skeja,
Daniel Gutierrez Espinoza and
Alex Wein; Preprint.
[arXiv]
We establish the first sharp thresholds for low-degree polynomial tests in planted-vs-planted settings, where the goal is to determine with vanishing error which of two structured planted mechanisms generated the observed data. We prove matching low-degree upper and lower bounds for counting communities in the planted submatrix and planted dense
subgraph models. The resulting testing threshold coincides, down to the sharp constant,
with the known low-degree recovery threshold. In contrast, the task of weak testing, where
the goal is to outperform random guessing, does not have a sharp threshold but rather a
smooth transition, which we identify.
To prove our results, we develop a framework for
planted-vs-planted testing that builds on a latent-variable expansion originating in lowdegree recovery and employs new methods to identify and prune non-signal contributions.
Note on edge expansion and modularity in preferential attachment graphs with Colin McDiarmid, Katarzyna Rybarczyk and Małgorzata Sulkowska; Preprint.
[arXiv]
Edge expansion is a parameter indicating how well-connected a graph is and is an important notion in theoretical computer science. Modularity measures of how well a graph can be partitioned into communities and is widely used in clustering applications. We study these two parameters in models of random preferential attachment graphs, with $h \geq 2$ edges added per step. We establish new bounds for the likely edge expansion for both random models. Using bounds for edge expansion of small subsets of vertices, we derive new upper bounds also for the modularity values for small $h$.
Universal lower bound for community structure of sparse graphs with Vilhelm Agdur and Nina Kamčev; Preprint.
[arXiv]
Modularity introduced by Newman and Girvan (link) is a popular metric in community detection.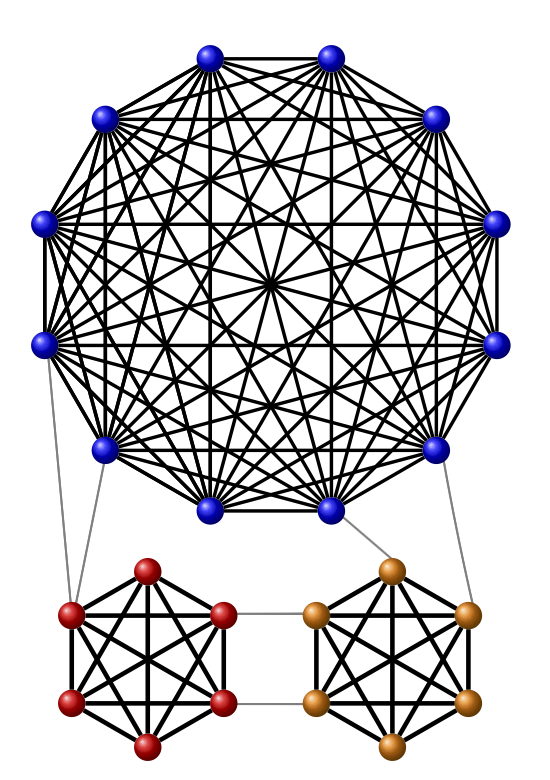
We prove new lower bounds on the modularity of graphs. Specifically, the modularity of a graph $G$ with average degree $\bar d$ is $Ω(\bar{d}^{-1/2})$, under some mild assumptions on the degree sequence of $G$. The lower bound $Ω(\bar{d}^{-1/2})$ applies, for instance, to graphs with a power-law degree sequence or a near-regular degree sequence.
It has been suggested that the relatively high modularity of the Erdős-Rényi random graph $G_{n,p}$ stems from the random fluctuations in its edge distribution, however our results imply high modularity for any graph with a degree sequence matching that typically found in $G_{n,p}$.
The proof of the new lower bound relies on certain weight-balanced bisections with few cross-edges, which build on ideas of Alon (see this paper) and may be of independent interest."
Modularity and partially observed graphs with Colin McDiarmid; Preprint.
[arXiv]
Suppose that there is an unknown underlying graph $G$ on a large vertex set, and we can test only a proportion of the possible edges to check whether they are present in $G$. If $G$ has high modularity, is the observed graph $G'$ likely to have high modularity? We see that this is indeed the case under a mild condition, in a natural model where we test edges at random. We find that $q^*(G') \geq q^*(G)-\varepsilon$ with probability at least $1-\varepsilon$, as long as the expected number edges in $G'$ is large enough. Similarly, $q^*(G') \leq q^*(G)+\varepsilon$ with probability at least $1-\varepsilon$, under the stronger condition that the expected average degree in $G'$ is large enough. Further, under this stronger condition, finding a good partition for $G'$ helps us to find a good partition for $G$.
Modularity introduced by Newman and Girvan (in this paper) is a popular metric in community detection.
Publications and accepted manuscripts
Do not hesitate to email if you have trouble accessing any of the manuscripts listed below.
23. On graphs with modularity zero or near-zero with Colin McDiarmid;
Electronic Journal of Combinatorics, to appear.
[arXiv]
Modularity introduced by Newman and Girvan (link) is a popular metric in community detection.
It is known that complete graphs and complete multipartite graphs have modularity zero.
We show that the least number of edges we may delete from the complete graph $K_n$ to obtain a graph with non-zero modularity is $\lfloor n/2\rfloor +1$. Similarly we determine the least number of edges we may delete from or add to a complete bipartite graph to reach non-zero modularity. We give some corresponding results for complete multipartite graphs, and a short proof that complete multipartite graphs have modularity zero.
We also analyse the modularity of very dense random graphs, and in particular
we find that there is a transition to modularity zero when the average degree
of the complementary graph drops below 1.
22. The stochastic block model has the overlap graph property for modularity
with Shankar Bhamidi, David Gamarnik, Remco van der Hofstad, Nelly Litvak, Paweł Prałat and Yasmin Tousinejad;
ICALP 2026.
[arXiv]
The overlap gap property (OGP) is a statement about the geometry of near-optimal solutions. Exhibiting OGP implies failure of a class of local algorithms; and has been observed to coincide with conjectured algorithmic limits in problems with statistical computational gap.
We consider the Stochastic Block Model (SBM), where the graph has a planted partition with $k$ equal-size blocks which form the `communities', and where, for parameters $p>q$, vertices within the same community connect with probability $p$, while vertices in different communities connect with probability $q$, independently across pairs of vertices. Modularity--based clustering algorithms have become ubiquitous in applications. This article studies theoretical limits of local algorithms based on the modularity score on the SBM.
We establish that modularity exhibits OGP on the SBM. This rules out a class of local algorithms based on modularity for recovery in the SBM, and shows slow mixing time for a related Markov Chain. Theoretically this is one of the few instances where OGP has been established for a `planted' model, as most such analyses to date consider the `null' model.
21. Logical limit laws for Mallows random permutations with
Tobias Müller and
Teun Verstraaten;
Electronic Journal of Combinatorics, 32 4 (2025).
[doi, arXiv]
A random permutation $\Pi_n$ of $\{1,\dots,n\}$ follows the $\DeclareMathOperator{\Mallows}{Mallows}\Mallows(n,q)$ distribution with parameter $q>0$ if $\mathbb{P} ( \Pi_n = \pi )$ is proportional to $\DeclareMathOperator{\inv}{inv} q^{\inv(\pi)}$ for all $\pi$. Here $\DeclareMathOperator{\inv}{inv} \inv(\pi) := |\{ i < j : \pi(i) > \pi(j) \}|$ denotes the number of inversions of $\pi$. We consider properties of permutations that can be expressed by the sentences of two different logical languages. Namely, the theory of one bijection ($\mathsf{TOOB}$), which describes permutations via a single binary relation, and the theory of two orders ($\mathsf{TOTO}$), where we describe permutations by two total orders. We say that the convergence law holds with respect to one of these languages if, for every sentence $\phi$ in the language, the probability $\mathbb{P} (\Pi_n\text{ satisfies } \phi)$ converges to a limit as $n\to\infty$. If moreover that limit is in the set $\{0,1\}$ for all sentences, then the zero-one law holds.
We will show that with respect to $\mathsf{TOOB}$ the $\Mallows(n,q)$ distribution satisfies the convergence law but not the zero-one law when $q=1$, when $0 < q < 1$ is fixed the zero-one law holds, and for fixed $q>1$ the convergence law fails.
We will prove that with respect to $\mathsf{TOTO}$ the $\Mallows(n,q)$ distribution satisfies the convergence law but not the zero-one law for any fixed $q\neq 1$, and that if $q=q(n)$ satisfies $1- 1/\log^*n < q < 1 + 1/\log^*n$ then $\Mallows(n,q)$ fails the convergence law. Here $\log^*$ denotes the discrete inverse of the tower function.
20. Approximating temporal modularity on graphs of small underlying treewidth with Vilhelm Agdur, Jess Enright, Laura Larios-Jones, Kitty Meeks, Ella Yates;
ALGOWIN 2025.
[doi, arXiv]
Modularity introduced by Newman and Girvan (link) is a popular metric in community detection.
In this paper we study temporal modularity via the lens of fixed parameter tractability.
19. Fast and Accurate Algorithms to Calculate Expected Modularity in Probabilistic Networks with Xin Shen, Matteo Magnani and Christian Rohner;
Scientific Reports, 15 19062 (2025).
[doi, arXiv]
Modularity introduced by Newman and Girvan (link) is a popular metric in community detection.
However, little research has been performed to develop efficient modularity calculation algorithms for probabilistic networks. Particularly, it is challenging to efficiently calculate expected modularity when all possible worlds are considered.
To address this problem, we propose two algorithms partitioning the possible worlds based on their modularities to significantly reduce the number of probability calculations. We evaluate the accuracy and time efficiency of our algorithms through comprehensive experiments.
18. From flip processes to dynamical systems on graphons with Jan Hladky, Frederik Garbe and Matas Šileikis;
Annales de l'Institut Henri Poincaré, 60 4 (2024).
[doi, arXiv]  We introduce a class of random graph processes, which we call flip processes. Each such process is given by a rule which is a function $\mathscr{R}:\mathscr{H}_k \rightarrow \mathscr{H}_k$ from all labelled $k$-vertex graphs into itself ($k$ is fixed). The process starts with a given $n$-vertex graph $G_0$. In each step, the graph $G_i$ is obtained by sampling $k$ random vertices $v_1,\ldots,v_k$ of $G_{i-1}$ and replacing the induced graph $F:=G_{i-1}[v_1,\ldots,v_k]$ by $\mathscr{R}(F)$. This class contains several previously studied processes including the Erd\H{o}s--R\'enyi random graph process and the triangle removal process. Actually, our definition of flip processes is more general, in that $\mathscr{R}(F)$ is a probability distribution on $\mathscr{H}_k$, thus allowing randomised replacements.
We introduce a class of random graph processes, which we call flip processes. Each such process is given by a rule which is a function $\mathscr{R}:\mathscr{H}_k \rightarrow \mathscr{H}_k$ from all labelled $k$-vertex graphs into itself ($k$ is fixed). The process starts with a given $n$-vertex graph $G_0$. In each step, the graph $G_i$ is obtained by sampling $k$ random vertices $v_1,\ldots,v_k$ of $G_{i-1}$ and replacing the induced graph $F:=G_{i-1}[v_1,\ldots,v_k]$ by $\mathscr{R}(F)$. This class contains several previously studied processes including the Erd\H{o}s--R\'enyi random graph process and the triangle removal process. Actually, our definition of flip processes is more general, in that $\mathscr{R}(F)$ is a probability distribution on $\mathscr{H}_k$, thus allowing randomised replacements.
Given a flip process with a rule $\mathscr{R}$, we construct time-indexed trajectories $\Phi: \mathscr{W}_{0} \times [0,\infty)\rightarrow \mathscr{W}_{0}$ in the space of graphons. We prove that for any $T > 0$ starting with a large finite graph $G_0$ which is close to a graphon $W_0$ in the cut norm, with high probability the flip process will stay in a thin sausage around the trajectory $(\Phi(W_0,t))_{t=0}^T$ (after rescaling).
These graphon trajectories are then studied from the perspective of dynamical systems. Among others topics, we study continuity properties of these trajectories with respect to time and initial graphon, existence and stability of fixed points and speed of convergence (whenever the infinite time limit exists). We give an example of a flip process with a periodic trajectory.
See also the paper Prominent examples of flip processes.
17. A branching process with deletions and mergers that matches the threshold for hypercube percolation with Laura Eslava and Sarah Penington;
Annales de l'Institut Henri Poincaré, 60 2 (2024). [doi, arXiv]
We define a graph process $G(p,q)$ based on a discrete branching process with deletions and mergers, which is inspired by the 4-cycle structure of both the hypercube $Q_d$ and the lattice $\mathbb{Z}^d$ for large $d$. Individuals have Poisson offspring distribution with mean $1+p$ and certain deletions and mergers occur with probability $q$; these parameters correspond to the mean number of edges discovered from a given vertex in an exploration of a percolation cluster and to the probability that a non-backtracking path of length four closes a cycle, respectively.
We prove survival and extinction under certain conditions on $p$ and $q$ that heuristically match the known expansions of the critical probabilities for bond percolation on the lattice $\mathbb{Z}^d$ and the hypercube $Q_d$. These expansions have been rigorously established by Hara and Slade in 1995, and van der Hofstad and Slade in 2006, respectively. We stress that our method does not constitute a branching process proof for the percolation threshold.
The analysis of the graph process survival is considerably more challenging than for branching processes in discrete time, due to the interdependence between the descendants of different individuals in the same generation. In fact, it is left open whether the survival probability of $G(p,q)$ is monotone in $p$ or $q$; we discuss this and some other open problems regarding the new graph process.
16. Modularity and graph expansion with Baptiste Louf and Colin McDiarmid;
ITCS 2024.
[doi, arXiv]
We relate two important notions in graph theory: expanders which are highly connected graphs, and modularity a parameter of a graph that is primarily used in community detection. More precisely, we show that a graph having modularity bounded below 1 is equivalent to it having a large subgraph which is an expander. 
We further show that a connected component $H$ will be split in an optimal partition of the host graph $G$ if and only if the relative size of $H$ in $G$ is greater than an expansion constant of $H$. This is a further exploration of the resolution limit known for modularity, and indeed recovers the bound that a connected component $H$ in the host graph $G$ will not be split if $e(H)<\sqrt{2e(G)}$.
15. Finding large expanders in graphs: from topological minors to induced subgraphs with Baptiste Louf;
Electronic Journal of Combinatorics, 30 1 (2023). [doi, arXiv]
A structural and geometric property of graphs is the presence of large expanders. The problem of finding such structures was considered by Krivelevich in this paper. Here, we show that the problem of finding a large induced subgraph that is an expander can be reduced to the simpler problem of finding a topological minor that is an expander. Our proof is constructive, which is helpful in an algorithmic setting.
We also show that every large subgraph of an expander graph contains a large subgraph which is itself an expander.
14. No additional tournaments are quasirandom-forcing with Robert Hancock, Adam Kabela, Dan Kráľ, Taísa Martins, Roberto Parente and Jan Volec;
European Journal of Combinatorics, 108 (2023). [doi, arXiv, slides]
A tournament $H$ is quasirandom-forcing if the following holds for every sequence $(G_n)_{n}$ of tournaments of growing orders: if the density of $H$ in $G_n$ converges to the expected density of $H$ in a random tournament, then $(G_n)_n$ is quasirandom. Every transitive tournament with at least 4 vertices is quasirandom-forcing (link), and Coregliano et al. showed that there is also a non-transitive 5-vertex tournament with the property (link). We show that no additional tournament has this property.
Random graph models with community structure have been studied extensively in the literature. For both the problems of detecting and recovering community structure, an interesting landscape of statistical and computational phase transitions has emerged. A natural unanswered question is: might it be possible to infer properties of the community structure (for instance, the number and sizes of communities) even in situations where actually finding those communities is believed to be computationally hard? We show the answer is no. In particular, we consider certain hypothesis testing problems between models with different community structures, and we show (in the low-degree polynomial framework) that testing between two options is as hard as finding the communities.13. Is it easier to count communities than find them? with Cynthia Rush,
Alex Wein and
Dana Yang;
Random Structures & Algorithms 68 4 2026 + ITCS 2023.
[doi,
arXiv]
Our methods give the first computational lower bounds for testing between two different `planted' distributions, whereas previous results have considered testing between a planted distribution and an i.i.d. `null' distribution.
In addition we show that under the low-degree framework any estimation problem in a signal plus noise model has an equivalent testing problem for testing between two planted models.
12. The modularity of random graphs on the hyperbolic plane with Jordan Chellig and Nikolaos Fountoulakis;
Journal of Complex Networks, 10 1 (2022). [doi, arXiv]
Modularity is a quantity which has been introduced in the context of complex networks in order to quantify how close a network is to an ideal modular network in which the nodes form small interconnected communities that are joined together with relatively few edges. In this paper, we consider this quantity on a recent probabilistic model of complex networks introduced by Krioukov et al. (Phys. Rev. E 2010).
This model views a complex network as an expression of hidden hierarchies, encapsulated by an underlying hyperbolic space. For certain parameters, this model was proved to have typical features that are observed in complex networks such as power law degree distribution, bounded average degree, clustering coefficient that is asymptotically bounded away from zero, and ultra-small typical distances. In the present work, we investigate its modularity and we show that, in this regime, it converges to 1 in probability.
11. Assigning times to minimise reachability in temporal graphs with Jess Enright and Kitty Meeks;
Journal of Computer and System Sciences, 115 (2022). [doi, arXiv]
Temporal graphs, in which edges are active at specified times, are of relevance for spreading processes on graphs. In our setting the number of active times for each edge is fixed, but we can change the relative order in which (sets of) edges are active. We investigate the problem of determining an ordering of edges that minimises the maximum number of vertices reachable from any single starting vertex. Epidemiologically, this corresponds to the worst-case number of vertices infected in a single disease outbreak.

10. The parameterised complexity of computing the maximum modularity of a graph with Kitty Meeks;
Algorithmica, 82 8 (2020) + IPEC 2018. [doi, IPEC, arXiv]
Determining the maximum modularity of a graph is known to be NP-complete in general, even to find a multiplicative approximation, but we show it has reduced complexity with respect to some structural parameterisations of the input graph. 
On the other hand we prove modularity is W[1]-hard (and hence unlikely to admit an FPT algorithm) when parameterised simultaneously by pathwidth and the size of a minimum feedback vertex set.
9. Embedding Small Digraphs and Permutations in Binary Trees and Split Trees with Michael Albert, Cecilia Holmgren and Tony Johansson;
Algorithmica, 82 3 (2020). [doi, arXiv, slides]
Given a tree on $n$ vertices, we randomly label the vertices 1 to $n$. An occurence of a length $k$ permutation $\sigma$ is a sequence of vertices on a common descending path in the tree whose labels, when read from root to leaf, are ordered according to $\sigma$. We calculate the number of occurences of fixed length permutations in binary trees and split trees. 
For the trees considered, this generalizes the inversion results below from $\sigma=21$ to more general permutations $\sigma$.
Conference version: Permutations in binary trees and split trees AofA
8. Modularity of Erdos-Renyi random graphs with Colin McDiarmid;
Random Structures and Algorithms, 57 1 (2020)
[doi, arXiv]
Modularity introduced by Newman and Girvan (in this paper) is a popular metric in community detection.
Two key features which we find for Erdos-Renyi random graphs are that the modularity is $1+o(1)$ with high probability (whp) for $np$ up to $1+o(1)$ (and no further); and when $np\geq 1$ and $p$ is bounded below 1, it has order $(np)^{-1/2}$ whp, in accord with a conjecture by Reichardt and Bornholdt in 2006 (and disproving another conjecture from the physics literature).
Conference version: AofA
7. Random tree recursions: which fixed points correspond to tangible sets of trees? with Toby Johnson and Moumanti Podder;
Random Structures and Algorithms, 56 3 (2020). [doi, arXiv] 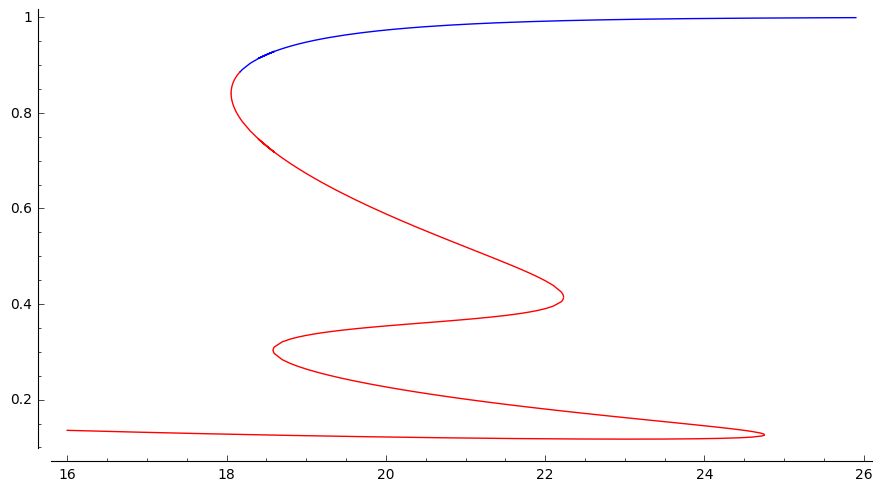 We answer the following question of Joel Spencer:
We answer the following question of Joel Spencer:
Say that a set of trees $B$ follows the at-least-two rule if $t \in B$
if and only if the root of $t$ has two children $u$ and $v$ such that the subtrees rooted at $u$ and $v$ are also in $B$. Suppose that $\lambda > \lambda_{crit}$. Does there exist a set of trees $B$ with this metaproperty such that for random tree $T_\lambda$, we have that $\mathbb{P}[T_\lambda \in B]$ is the middle solution of the classical fixed point equation?
6. $k$ cuts on paths and some trees with Xing Shi Cai, Cecilia Holmgren and Luc Devroye;
Electronic Journal of Probability, 24 (2019). [doi, arXiv]
We define a new cutting process on trees the `blunt scissors' or $k$-cut model where each node must be cut $k$ times before it is destroyed. For $k=1$ this is the model of Meir and Moon. This paper studies the distribution of the $k$-cut number of a path on $n$ vertices.

5. Inversions in split trees and Galton-Watson trees with Xing Shi Cai, Cecilia Holmgren, Svante Janson and Tony Johansson;
Combinatorics, Probability and Computing, 28 3 (2019). [doi, arXiv]
We study $I(T)$, the number of inversions in a tree $T$ with its vertices labeled uniformly
at random, which is a generalization of inversions in permutations. We first show that the
cumulants of $I(T)$ have explicit formulas involving the $k$-total common ancestors of $T$ (an
extension of the total path length). For three sequence of trees $T_n$ we consider $X_n$ the normalized version of $I(T_n)$.
We identify the limit of $X_n$ for complete $b$-ary trees. For
$T_n$ being split trees, we show that $X_n$ converges to the unique solution of a distributional
equation and when $T_n$’s are conditional Galton–Watson trees, we show that $X_n$ converges
to a random variable defined in terms of Brownian excursions. By exploiting the connection
between inversions and the total path length, we extend earlier results by Panholzer and Seitz.
Conference version: [AofA]
4. Modularity of regular and treelike graphs with Colin McDiarmid;
Journal of Complex Networks, 6 4 (2018) [doi, arXiv] 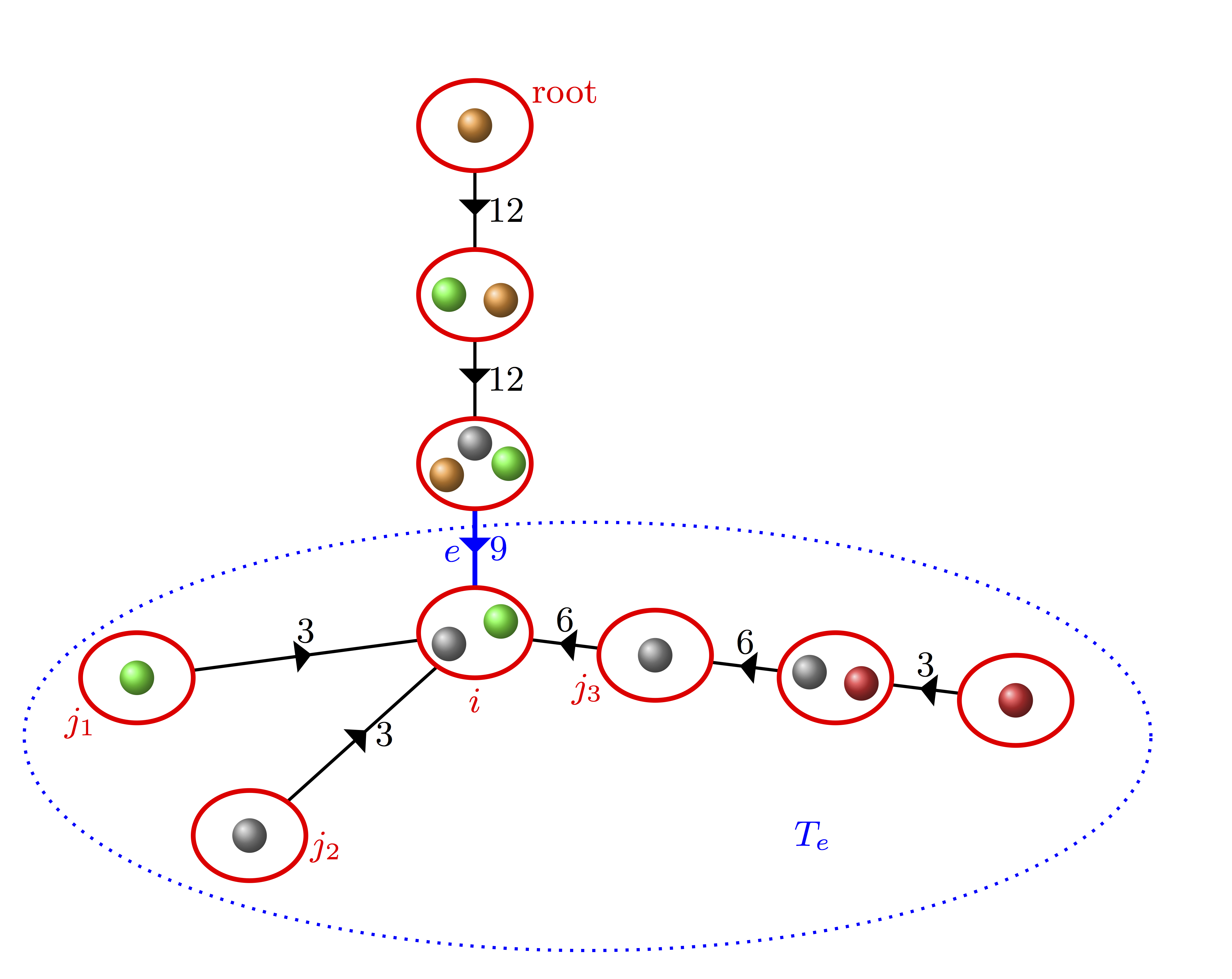 Modularity introduced by Newman and Girvan (in this paper) is a popular metric in community detection.
Modularity introduced by Newman and Girvan (in this paper) is a popular metric in community detection.
We show that random cubic graphs usually have modularity in the interval (0.666, 0.804); and random $r$-regular graphs for large $r$ usually have modularity $\Theta(1/\sqrt{r})$. Our results give thresholds for the statistical significance of clustering found in large regular networks.
The modularity of cycles and low degree trees is known to be asymptotically 1. We extend these results to all graphs whose product of treewidth and maximum degree is much less than the number of edges. This shows for example that random planar graphs typically have modularity close to 1.
3. Guessing Numbers of Odd Cycles with Ross Atkins and Puck Rombach;
Electronic Journal of Combinatorics, 24 1 (2017). [doi, arXiv] 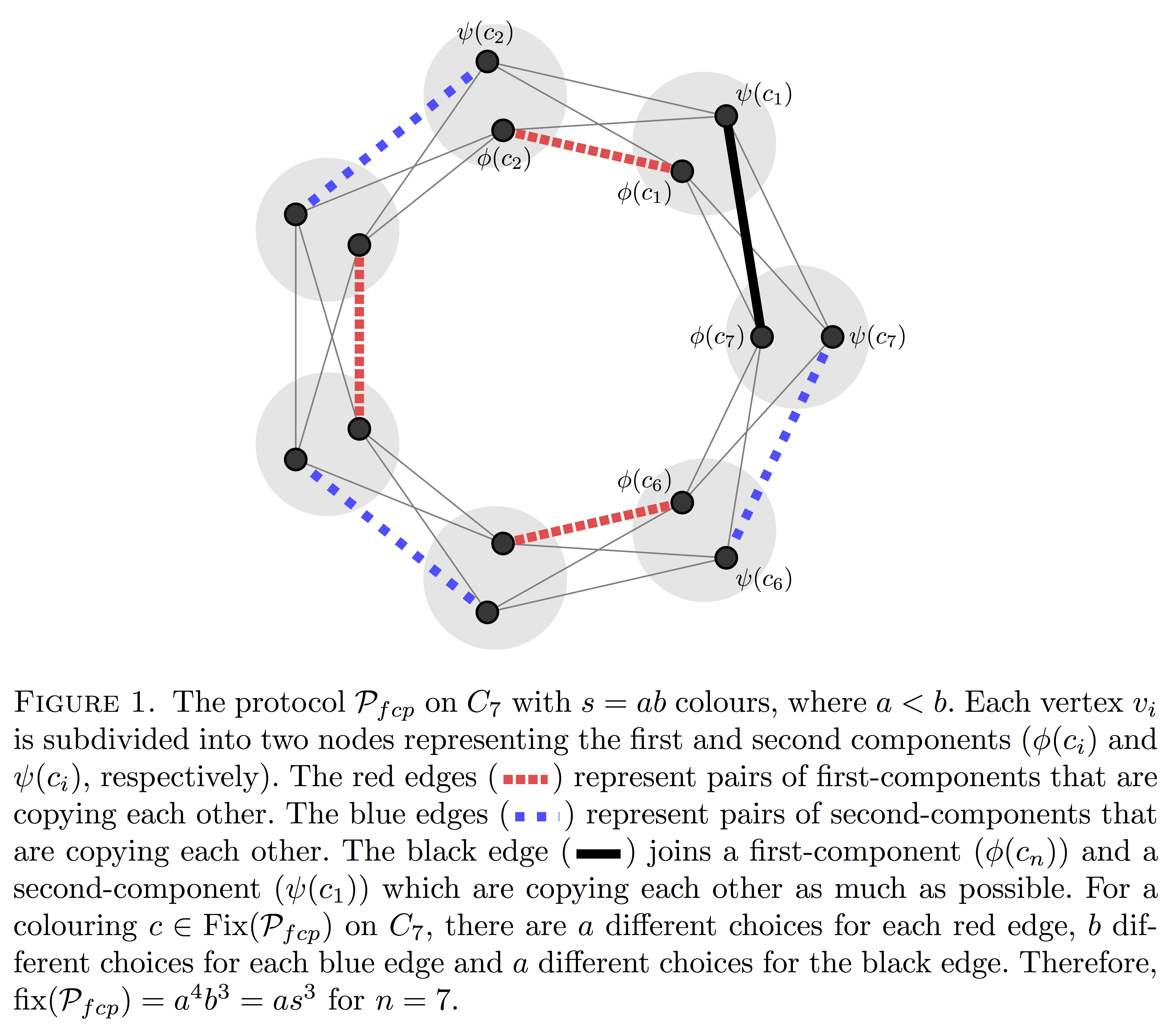 For a given number of colours, $s$, the guessing number of a graph is the base $s$ logarithm
of the size of the largest family of colourings of the vertex set of the graph such that the colour
of each vertex can be determined from the colours of the vertices in its neighbourhood. We show that, for any given
integer $s \geq 2$, if $a$ is the largest factor of $s$ less than or equal to $\sqrt{s}$, for sufficiently large odd $n$,
the guessing number of the cycle $C_n$ with $s$ colours is $(n -1)/2 + \log_s (a)$. This answers a question posed in this paper by
Christofides and Markstrom in 2011.
For a given number of colours, $s$, the guessing number of a graph is the base $s$ logarithm
of the size of the largest family of colourings of the vertex set of the graph such that the colour
of each vertex can be determined from the colours of the vertices in its neighbourhood. We show that, for any given
integer $s \geq 2$, if $a$ is the largest factor of $s$ less than or equal to $\sqrt{s}$, for sufficiently large odd $n$,
the guessing number of the cycle $C_n$ with $s$ colours is $(n -1)/2 + \log_s (a)$. This answers a question posed in this paper by
Christofides and Markstrom in 2011.
2. Degree sequences of random digraphs and bipartite graphs with Brendan McKay;
Journal of Combinatorics, 7 1 (2016). [doi, arXiv] [pdf] We investigate the joint distribution of the vertex degrees in three models of random bipartite graphs. Namely, we can choose each edge with a specified probability, choose a specified number of edges, or specify the vertex degrees in one of the two colour classes.
We investigate the joint distribution of the vertex degrees in three models of random bipartite graphs. Namely, we can choose each edge with a specified probability, choose a specified number of edges, or specify the vertex degrees in one of the two colour classes.
In each case, provided the two colour classes are not too different in size nor the number of edges too low, we define a probability space based on independent binomial variables and show that its probability masses asymptotically equal those of the degrees in the graph model almost everywhere. The accuracy is sufficient to asymptotically determine the expectation of any joint function of the degrees whose maximum is at most polynomially greater than its expectation.
1. Avoider-Enforcer Star Games with Andrzej Grzesik, Mirjana Mikalački, Zoltán Nagy, Alon Naor, Balázs Patkós;
Discrete Mathematics and Theoretical Computer Science, 17 1 (2015). [doi, arXiv]
 In this paper, we study $(1 : b)$ Avoider-Enforcer games played on the edge set of the complete graph on n vertices.
For every constant $k \geq 3$ we analyse the $k$-star game, where Avoider tries to avoid claiming $k$ edges incident to
the same vertex. We consider both versions of Avoider-Enforcer games - the strict and the monotone - and for each
provide explicit winning strategies for both players. We determine the order of magnitude of the threshold biases
$f_\mathcal{F}^{mon}$, $f_\mathcal{F}^{-}$ and $f_\mathcal{F}^{+}$, where $\mathcal{F}$ is the hypergraph of the game.
In this paper, we study $(1 : b)$ Avoider-Enforcer games played on the edge set of the complete graph on n vertices.
For every constant $k \geq 3$ we analyse the $k$-star game, where Avoider tries to avoid claiming $k$ edges incident to
the same vertex. We consider both versions of Avoider-Enforcer games - the strict and the monotone - and for each
provide explicit winning strategies for both players. We determine the order of magnitude of the threshold biases
$f_\mathcal{F}^{mon}$, $f_\mathcal{F}^{-}$ and $f_\mathcal{F}^{+}$, where $\mathcal{F}$ is the hypergraph of the game.
Online Talks
(55 min) Testing between planted distributions and connections to recovery. MSRI / SLMath Apr. 2025 [video](20 min) Modularity and Graph Expansion. ITCS, Jan. 2024 [video] [slides]
(25 min) Is it easier to count communities than find them? ITCS, Jan. 2023 [video]
(55 min) Partially observing graphs, when can we infer community structure? Topos Institute, Dec. 2021 [video]
(20 min) Modularity and Edge Sampling. Banff, Aug. 2021 [video] [slides]